根據<< A Neural Algorithm of Artistic Style >>,畫家所畫的作品可以分成內容(content)和風格(style),此次要撰寫的程式需要兩張圖片-風格圖片以及內容圖片,使用風格圖片學習畫作的風格並和內容圖片的內容進行結合,產生一張新圖片(同時具有風格圖片風格和內容圖片的內容)。 +
+ =
=
既然是使用神經網路進行學習必定需要求loss,但在求loss前我們先了解圖案在不同層CNN進行重塑的結果(下面圖出自於論文)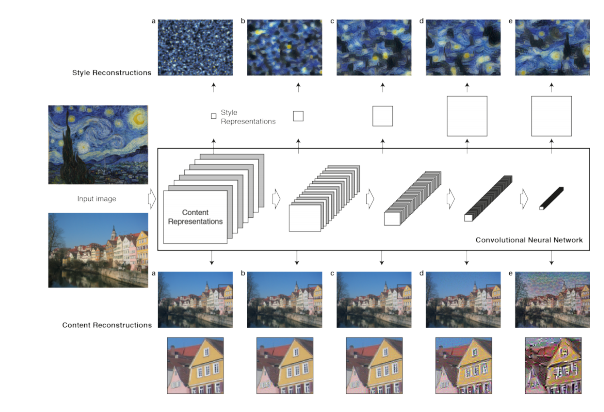
論文中使用的是vgg19(pretrained=True)的網路架構
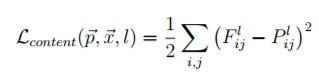
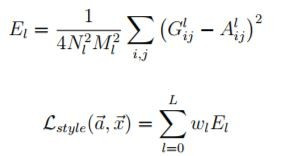
(程式碼基本上都出自於pytorch的Tutorials,加上註解)
https://pytorch.org/tutorials/advanced/neural_style_tutorial.html
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import copy
import matplotlib.pyplot as plt
from torchvision import models
from torchvision import transforms
from PIL import Image
imgsize = 128
loader = transforms.Compose(
[
transforms.Resize(imgsize),
transforms.ToTensor(),
]
)
def image_loader(image_name):
image = Image.open(image_name)
image = loader(image) #調整圖片大小並且轉為tensor
image = torch.unsqueeze(image,dim=0) #調整至Conv2d的輸入格式
image = image.float()
return image
style_img = image_loader(".\image2\picasso.jpg") #風格圖片
content_img = image_loader(".\image2\dancing.jpg") #內容圖片
assert style_img.size() == content_img.size() #確保風格圖片和內容圖片大小相同
class Contentloss(nn.Module):
def __init__(self,target):
super().__init__()
self.target = target.detach()
def forward(self,input):
self.loss = F.mse_loss(input,self.target)
return input
def gram_matrix(input):
a,b,c,d = input.shape #a=batch_size b=featuremap c,d=length*height
features = input.view(a*b,c*d) #轉為矩陣形式
G = torch.mm(features,features.t()) #計算Gram matrix
return G.div(a*b*c*d)
class Styleloss(nn.Module):
def __init__(self,target_feature):
super().__init__()
self.target = gram_matrix(target_feature).detach()
def forward(self,input):
G = gram_matrix(input)
self.loss = F.mse_loss(G,self.target)
return input
cnn = models.vgg19(pretrained=True).features.eval() #pretrained = true表示保留參數值
cnn_normalization_mean = torch.tensor([0.485,0.456,0.406])
cnn_normalization_std = torch.tensor([0.229,0.224,0.225])
class Normalization(nn.Module):
def __init__(self,mean,std):
super().__init__()
self.mean = torch.tensor(mean).view(-1,1,1)
self.std = torch.tensor(std).view(-1,1,1)
def forward(self,img):
return (img-self.mean)/self.std
def get_style_model_and_losses(cnn,normalization_mean,normalization_std,style_img,content_img,content_layers=content_layers_default,style_layers=style_layers_default):
cnn = copy.deepcopy(cnn)
normalization = Normalization(normalization_mean,normalization_std)
content_losses=[] #用來存放content loss網路層的list
style_losses=[] #用來存放style loss網路層的list
model = nn.Sequential(normalization) #加入第一層標準化層
i=0
for layer in cnn.children():
if isinstance(layer, nn.Conv2d):
i=i+1
name = 'conv_{}'.format(i)
elif isinstance(layer, nn.ReLU):
name = 'relu_{}'.format(i)
layer = nn.ReLU(inplace=False)
elif isinstance(layer, nn.MaxPool2d):
name = 'pool_{}'.format(i)
elif isinstance(layer, nn.BatchNorm2d):
name = 'bn_{}'.format(i)
else:
raise RuntimeError('Unrecognized layer: {}'.format(layer.__class__.__name__))
model.add_module(name,layer)
if name in content_layers:
target = model(content_img).detach()
content_loss = Contentloss(target)#創建content loss網路層
#並將target傳入init
model.add_module("content_loss_{}".format(i),content_loss)
content_losses.append(content_loss)#添加的是網路層
if name in style_layers:
target_feature = model(style_img).detach()
style_loss = Styleloss(target_feature)#創建style loss網路層
#並將target傳入init
model.add_module("style_loss_{}".format(i),style_loss)#添加的是網路層
style_losses.append(style_loss)
for i in range(len(model)-1,-1,-1):
if isinstance(model[i],Contentloss) or isinstance(model[i],Styleloss):
break
model = model[:i+1]
return model,style_losses,content_losses
input_img = content_img.clone() #可以是內容圖片或白噪聲
def get_input_optimizer(input_img): #採用論文中建議的LBFGS
optimizer = optim.LBFGS([input_img.requires_grad_()])
return optimizer
def run_style_transfer(cnn,normalization_mean,normalization_std,content_img,style_img,input_img,num_setps=300,style_weight=1000000,content_weight=1):
print('Building the style transfer model...')
model,style_losses,content_losses = get_style_model_and_losses(cnn,normalization_mean,normalization_std,style_img,content_img)
print(model)
optimizer = get_input_optimizer(input_img)
print('optimizimg...')
run = [0]
while run[0]<= num_setps:
def closure():
input_img.data.clamp_(0,1)
optimizer.zero_grad()
model(input_img)
style_score = 0
content_score = 0
for s1 in style_losses:
style_score = style_score+s1.loss
for c1 in content_losses:
content_score = content_score+c1.loss
style_score = style_weight*style_score
content_score = content_weight*content_score
loss = style_score + content_score
loss.backward()
run[0] = run[0]+1
if run[0] % 50 == 0:
print("run{}:".format(run))
print('style loss:{:4f} content loss:{:4f}'.format(style_score.item(),content_score.item()))
print()
return style_score + content_score
optimizer.step(closure)
input_img.data.clamp_(0,1)
return input_img
 abc93314
abc93314
